All in One View
Content from Automated Version Control
Last updated on 2025-05-22 | Edit this page
Estimated time: 5 minutes
Overview
Questions
- What is version control and why should I use it?
Objectives
- Understand the benefits of an automated version control system.
- Understand the basics of how automated version control systems work.
Original lesson material: https://swcarpentry.github.io/git-novice/ Slides: https://esciencecenter-digital-skills.github.io/digital-skills-slides/modules/git-lesson/git-slides, until https://esciencecenter-digital-skills.github.io/digital-skills-slides/modules/git-lesson/git-slides#/4.
The slides can be used to explain the concepts introduced in the text here.
We’ll start by exploring how version control can be used to keep track of what one person did and when. Even if you aren’t collaborating with other people, automated version control is much better than this situation:

We’ve all been in this situation before: it seems unnecessary to have multiple nearly-identical versions of the same document. Some word processors let us deal with this a little better, such as Microsoft Word’s Track Changes, Google Docs’ version history, or LibreOffice’s Recording and Displaying Changes.
Version control systems start with a base version of the document and then record changes you make each step of the way. You can think of it as a recording of your progress: you can rewind to start at the base document and play back each change you made, eventually arriving at your more recent version.

Once you think of changes as separate from the document itself, you can then think about “playing back” different sets of changes on the base document, ultimately resulting in different versions of that document. For example, two users can make independent sets of changes on the same document.

Unless multiple users make changes to the same section of the document - a conflict - you can incorporate two sets of changes into the same base document.

A version control system is a tool that keeps track of these changes for us, effectively creating different versions of our files. It allows us to decide which changes will be made to the next version (each record of these changes is called a commit), and keeps useful metadata about them. The complete history of commits for a particular project and their metadata make up a repository. Repositories can be kept in sync across different computers, facilitating collaboration among different people.
Automated version control systems are nothing new. Tools like RCS, CVS, or Subversion have been around since the early 1980s and are used by many large companies. However, many of these are now considered legacy systems (i.e., outdated) due to various limitations in their capabilities. More modern systems, such as Git and Mercurial, are distributed, meaning that they do not need a centralized server to host the repository. These modern systems also include powerful merging tools that make it possible for multiple authors to work on the same files concurrently.
Paper Writing
Imagine you drafted an excellent paragraph for a paper you are writing, but later ruin it. How would you retrieve the excellent version of your conclusion? Is it even possible?
Imagine you have 5 co-authors. How would you manage the changes and comments they make to your paper? If you use LibreOffice Writer or Microsoft Word, what happens if you accept changes made using the
Track Changesoption? Do you have a history of those changes?
Recovering the excellent version is only possible if you created a copy of the old version of the paper. The danger of losing good versions often leads to the problematic workflow illustrated in the PhD Comics cartoon at the top of this page.
Collaborative writing with traditional word processors is cumbersome. Either every collaborator has to work on a document sequentially (slowing down the process of writing), or you have to send out a version to all collaborators and manually merge their comments into your document. The ‘track changes’ or ‘record changes’ option can highlight changes for you and simplifies merging, but as soon as you accept changes you will lose their history. You will then no longer know who suggested that change, why it was suggested, or when it was merged into the rest of the document. Even online word processors like Google Docs or Microsoft Office Online do not fully resolve these problems.
- Version control is like an unlimited ‘undo’.
- Version control also allows many people to work in parallel.
Content from Setting Up Git
Last updated on 2025-05-22 | Edit this page
Estimated time: 10 minutes
Overview
Questions
- How do I get set up to use Git?
Objectives
- Configure
gitthe first time it is used on a computer. - Understand the meaning of the
--globalconfiguration flag.
There are no slides for this episode. Explain what a command line is, why it is useful, and why we use it in this workshop. Participants are often new to the command line and don’t get why we not use a git gui. Only focus on the bare essentials for setting up git. We shall use nano editor so that everyone is on the same page.
When we use Git on a new computer for the first time, we need to configure a few things. Below are a few examples of configurations we will set as we get started with Git:
- our name and email address,
- what our preferred text editor is,
- and that we want to use these settings globally (i.e. for every project).
On a command line, Git commands are written as
git verb options, where verb is what we
actually want to do and options is additional optional
information which may be needed for the verb. So here is
how Dracula sets up his new laptop:
BASH
$ git config --global user.name "Vlad Dracula"
$ git config --global user.email "vlad@tran.sylvan.ia"Please use your own name and email address instead of Dracula’s. This user name and email will be associated with your subsequent Git activity, which means that any changes pushed to GitHub, BitBucket, GitLab or another Git host server after this lesson will include this information.
For this lesson, we will be interacting with GitHub and so the email address used should be the same as the one used when setting up your GitHub account. If you are concerned about privacy, please review GitHub’s instructions for keeping your email address private.
If you elect to use a private email address with GitHub, then use
GitHub’s no-reply email address for the user.email value.
It looks like ID+username@users.noreply.github.com. You can
look up your own address in your GitHub email settings.
When working with git bash, you may run into a warning on line endings:
As with other keys, when you hit Enter or ↵ or on Macs, Return on your keyboard, your computer encodes this input as a character. Different operating systems use different character(s) to represent the end of a line. (You may also hear these referred to as newlines or line breaks.) Because Git uses these characters to compare files, it may cause unexpected issues when editing a file on different machines. Though it is beyond the scope of this lesson, you can read more about this issue in the Pro Git book.
You can change the way Git recognizes and encodes line endings using
the core.autocrlf command to git config. The
following settings are recommended:
On macOS and Linux:
And on Windows:
Set your text editor to nano. nano is a
simple to use command-line editor, and we recommend to use it during
this lesson.
Execute the following command:
You can configure a different editor than nano if you
wish. Here are a few examples:
| Editor | Configuration command |
|---|---|
| Atom | $ git config --global core.editor "atom --wait" |
| BBEdit (Mac, with command line tools) | $ git config --global core.editor "bbedit -w" |
| Sublime Text (Mac) | $ git config --global core.editor "/Applications/Sublime\ Text.app/Contents/SharedSupport/bin/subl -n -w" |
| Sublime Text (Win, 32-bit install) | $ git config --global core.editor "'c:/program files (x86)/sublime text 3/sublime_text.exe' -w" |
| Sublime Text (Win, 64-bit install) | $ git config --global core.editor "'c:/program files/sublime text 3/sublime_text.exe' -w" |
| Notepad (Win) | $ git config --global core.editor "c:/Windows/System32/notepad.exe" |
| Notepad++ (Win, 32-bit install) | $ git config --global core.editor "'c:/program files (x86)/Notepad++/notepad++.exe' -multiInst -notabbar -nosession -noPlugin" |
| Notepad++ (Win, 64-bit install) | $ git config --global core.editor "'c:/program files/Notepad++/notepad++.exe' -multiInst -notabbar -nosession -noPlugin" |
| Kate (Linux) | $ git config --global core.editor "kate" |
| Gedit (Linux) | $ git config --global core.editor "gedit --wait --new-window" |
| Scratch (Linux) | $ git config --global core.editor "scratch-text-editor" |
| Emacs | $ git config --global core.editor "emacs" |
| Vim | $ git config --global core.editor "vim" |
| VS Code | $ git config --global core.editor "code --wait" |
It is possible to reconfigure the text editor for Git whenever you want to change it.
Default Git branch naming
Source file changes are associated with a “branch.” For new learners
in this lesson, it’s enough to know that branches exist, and this lesson
uses one branch.
Previously, by default, Git would create a branch called
master instead of main, when you create a new
repository with git init (as explained in the next
Episode). This term evokes the racist practice of human slavery and the
software development
community has moved to adopt more inclusive language.
In 2020, most Git code hosting services transitioned to using
main as the default branch.
The five commands we just ran above only need to be run once: the
flag --global tells Git to use the settings for every
project, in your user account, on this computer.
Let’s review those settings and test our core.editor
right away:
Let’s close the file without making any additional changes. Remember, since typos in the config file will cause issues, it’s safer to view the configuration with:
And if necessary, change your configuration using the same commands to choose another editor or update your email address. This can be done as many times as you want.
Git Help and Manual
Always remember that if you forget the subcommands or options of a
git command, you can access the relevant list of options
typing git <command> -h or access the corresponding
Git manual by typing git <command> --help, e.g.:
While viewing the manual, remember the : is a prompt
waiting for commands and you can press Q to exit the
manual.
More generally, you can get the list of available git
commands and further resources of the Git manual typing:
- Use
git configwith the--globaloption to configure a user name, email address, editor, and other preferences once per machine.
Content from Creating a Repository
Last updated on 2025-05-15 | Edit this page
Estimated time: 15 minutes
Overview
Questions
- Where does Git store information?
Objectives
- Create a local Git repository.
- Describe the purpose of the
.gitdirectory.
Introduce here the story of Wolfman and Dracula. The examples make more sense if you introduce the story. Here we suggest referring to ‘The Holy Realms of Git’ slide: https://esciencecenter-digital-skills.github.io/digital-skills-slides/modules/git-lesson/git-slides#/5 to introduce the idea of repository and .git.
Once Git is configured, we can start using it.
We will continue with the story of Wolfman and Dracula who are investigating if it is possible to send a planetary lander to Mars.
 Werewolf
vs dracula by b-maze
/ Deviant Art. Mars
by European Space Agency / CC-BY-SA 3.0
IGO. Pluto
/ Courtesy NASA/JPL-Caltech. Mummy
© Gilad Fried / The Noun
Project / CC BY
3.0. Moon ©
Luc Viatour / https://lucnix.be / CC BY-SA
3.0.
Werewolf
vs dracula by b-maze
/ Deviant Art. Mars
by European Space Agency / CC-BY-SA 3.0
IGO. Pluto
/ Courtesy NASA/JPL-Caltech. Mummy
© Gilad Fried / The Noun
Project / CC BY
3.0. Moon ©
Luc Viatour / https://lucnix.be / CC BY-SA
3.0.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
First, let’s create a new directory in the Desktop
folder for our work and then change the current working directory to the
newly created one:
Then we tell Git to make planets a repository -- a place where Git can
store versions of our files:
It is important to note that git init will create a
repository that can include subdirectories and their files—there is no
need to create separate repositories nested within the
planets repository, whether subdirectories are present from
the beginning or added later. Also, note that the creation of the
planets directory and its initialization as a repository
are completely separate processes.
If we use ls to show the directory’s contents, it
appears that nothing has changed:
But if we add the -a flag to show everything, we can see
that Git has created a hidden directory within planets
called .git:
OUTPUT
. .. .gitGit uses this special subdirectory to store all the information about
the project, including the tracked files and sub-directories located
within the project’s directory. If we ever delete the .git
subdirectory, we will lose the project’s history.
Next, we will change the default branch to be called
main. This might be the default branch depending on your
settings and version of git. See the setup episode for
more information on this change.
OUTPUT
Switched to a new branch 'main'We can check that everything is set up correctly by asking Git to tell us the status of our project:
OUTPUT
On branch main
No commits yet
nothing to commit (create/copy files and use "git add" to track)If you are using a different version of git, the exact
wording of the output might be slightly different.
Places to Create Git Repositories
Along with tracking information about planets (the project we have
already created), Dracula would also like to track information about
moons. Despite Wolfman’s concerns, Dracula creates a moons
project inside his planets project with the following
sequence of commands:
BASH
$ cd ~/Desktop # return to Desktop directory
$ cd planets # go into planets directory, which is already a Git repository
$ ls -a # ensure the .git subdirectory is still present in the planets directory
$ mkdir moons # make a subdirectory planets/moons
$ cd moons # go into moons subdirectory
$ git init # make the moons subdirectory a Git repository
$ ls -a # ensure the .git subdirectory is present indicating we have created a new Git repositoryIs the git init command, run inside the
moons subdirectory, required for tracking files stored in
the moons subdirectory?
No. Dracula does not need to make the moons subdirectory
a Git repository because the planets repository can track
any files, sub-directories, and subdirectory files under the
planets directory. Thus, in order to track all information
about moons, Dracula only needed to add the moons
subdirectory to the planets directory.
Additionally, Git repositories can interfere with each other if they
are “nested”: the outer repository will try to version-control the inner
repository. Therefore, it’s best to create each new Git repository in a
separate directory. To be sure that there is no conflicting repository
in the directory, check the output of git status. If it
looks like the following, you are good to go to create a new repository
as shown above:
OUTPUT
fatal: Not a git repository (or any of the parent directories): .git-
git initinitializes a repository. - Git stores all of its repository data in the
.gitdirectory.
Content from Tracking Changes
Last updated on 2025-05-22 | Edit this page
Estimated time: 25 minutes
Overview
Questions
- How do I record changes in Git?
- How do I check the status of my version control repository?
- How do I record notes about what changes I made and why?
Objectives
- Go through the modify-add-commit cycle for one or more files.
- Explain where information is stored at each stage of that cycle.
- Distinguish between descriptive and non-descriptive commit messages.
We suggest to use slides. From slide 5 onwards: https://esciencecenter-digital-skills.github.io/digital-skills-slides/modules/git-lesson/git-slides#/5 Please switch back and forth between command line and slides when necessary.
First let’s make sure we’re still in the right directory. You should
be in the planets directory.
Let’s create a file called mars.txt that contains some
notes about the Red Planet’s suitability as a base. We’ll use
nano to edit the file; you can use whatever editor you
like. In particular, this does not have to be the
core.editor you set globally earlier. But remember, the
bash command to create or edit a new file will depend on the editor you
choose (it might not be nano). For a refresher on text
editors, check out “Which
Editor?” in The Unix Shell
lesson.
Type the text below into the mars.txt file:
OUTPUT
Cold and dry, but everything is my favorite colorLet’s first verify that the file was properly created by running the
list command (ls):
OUTPUT
mars.txtmars.txt contains a single line, which we can see by
running:
OUTPUT
Cold and dry, but everything is my favorite colorIf we check the status of our project again, Git tells us that it’s noticed the new file:
OUTPUT
On branch main
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
mars.txt
nothing added to commit but untracked files present (use "git add" to track)The “untracked files” message means that there’s a file in the
directory that Git isn’t keeping track of. We can tell Git to track a
file using git add:
and then check that the right thing happened:
OUTPUT
On branch main
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: mars.txt
Git now knows that it’s supposed to keep track of
mars.txt, but it hasn’t recorded these changes as a commit
yet. To get it to do that, we need to run one more command:
OUTPUT
[main (root-commit) f22b25e] Start notes on Mars as a base
1 file changed, 1 insertion(+)
create mode 100644 mars.txtWhen we run git commit, Git takes everything we have
told it to save by using git add and stores a copy
permanently inside the special .git directory. This
permanent copy is called a commit
(or revision) and its short
identifier is f22b25e. Your commit may have another
identifier.
We use the -m flag (for “message”) to record a short,
descriptive, and specific comment that will help us remember later on
what we did and why. If we just run git commit without the
-m option, Git will launch nano (or whatever
other editor we configured as core.editor) so that we can
write a longer message.
Good commit
messages start with a brief (<50 characters) statement about the
changes made in the commit. Generally, the message should complete the
sentence “If applied, this commit will”
Choosing a Commit Message
You are making changes to your code, where you added a new function to calculate the mean. During this you also realise that you made a typo in the use guide.
Which of the following commit messages would be most appropriate?
- “Changes”
- “Added calc_mean to stats.py and fixed typos”
- “Add a function to calculate the mean” “Fix typos in introduction of the user guide”
Answer 1 is not descriptive enough, and the purpose of the commit is unclear; and answer 2 is redundant to using “git diff” to see what changed in this commit and the commit is combining different changes; but answer 3 is good: short, descriptive, and imperative. It also separates the changes into 2 commits
If we run git status now:
OUTPUT
On branch main
nothing to commit, working tree cleanit tells us everything is up to date. If we want to know what we’ve
done recently, we can ask Git to show us the project’s history using
git log:
OUTPUT
commit f22b25e3233b4645dabd0d81e651fe074bd8e73b
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 09:51:46 2013 -0400
Start notes on Mars as a basegit log lists all commits made to a repository in
reverse chronological order. The listing for each commit includes the
commit’s full identifier (which starts with the same characters as the
short identifier printed by the git commit command
earlier), the commit’s author, when it was created, and the log message
Git was given when the commit was created.
Where Are My Changes?
If we run ls at this point, we will still see just one
file called mars.txt. That’s because Git saves information
about files’ history in the special .git directory
mentioned earlier so that our filesystem doesn’t become cluttered (and
so that we can’t accidentally edit or delete an old version).
Now suppose Dracula adds more information to the file. (Again, we’ll
edit with nano and then cat the file to show
its contents; you may use a different editor, and don’t need to
cat.)
OUTPUT
Cold and dry, but everything is my favorite color
The two moons may be a problem for WolfmanWhen we run git status now, it tells us that a file it
already knows about has been modified:
OUTPUT
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: mars.txt
no changes added to commit (use "git add" and/or "git commit -a")The last line is the key phrase: “no changes added to commit”. We
have changed this file, but we haven’t told Git we will want to save
those changes (which we do with git add) nor have we saved
them (which we do with git commit). So let’s do that now.
It is good practice to always review our changes before saving them. We
do this using git diff. This shows us the differences
between the current state of the file and the most recently saved
version:
OUTPUT
diff --git a/mars.txt b/mars.txt
index df0654a..315bf3a 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1 +1,2 @@
Cold and dry, but everything is my favorite color
+The two moons may be a problem for WolfmanThe output is cryptic because it is actually a series of commands for
tools like editors and patch telling them how to
reconstruct one file given the other. If we break it down into
pieces:
- The first line tells us that Git is producing output similar to the
Unix
diffcommand comparing the old and new versions of the file. - The second line tells exactly which versions of the file Git is
comparing;
df0654aand315bf3aare unique computer-generated labels for those versions. - The third and fourth lines once again show the name of the file being changed.
- The remaining lines are the most interesting, they show us the
actual differences and the lines on which they occur. In particular, the
+marker in the first column shows where we added a line.
After reviewing our change, it’s time to commit it:
OUTPUT
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: mars.txt
no changes added to commit (use "git add" and/or "git commit -a")Whoops: Git won’t commit because we didn’t use git add
first. Let’s fix that:
OUTPUT
[main 34961b1] Add concerns about effects of Mars' moons on Wolfman
1 file changed, 1 insertion(+)Git insists that we add files to the set we want to commit before actually committing anything. This allows us to commit our changes in stages and capture changes in logical portions rather than only large batches. For example, suppose we’re adding a few citations to relevant research to our thesis. We might want to commit those additions, and the corresponding bibliography entries, but not commit some of our work drafting the conclusion (which we haven’t finished yet).
To allow for this, Git has a special staging area where it keeps track of things that have been added to the current changeset but not yet committed.
If you think of Git as taking snapshots of changes over the life of a
project, git add specifies what will go in a
snapshot (putting things in the staging area), and
git commit then actually takes the snapshot, and
makes a permanent record of it (as a commit). If you don’t have anything
staged when you type git commit, Git will prompt you to use
git commit -a or git commit --all, which is
kind of like gathering everyone to take a group photo! However,
it’s almost always better to explicitly add things to the staging area,
because you might commit changes you forgot you made. (Going back to the
group photo simile, you might get an extra with incomplete makeup
walking on the stage for the picture because you used
-a!)
If you do accidentally add a file and you want to undo it, you can
use: git restore <filename> or
git revert <filename> to do this. However, these
functionalities of git are beyond the scope of this course.
Try to stage things manually, or you might find yourself searching for “git undo commit” more than you would like!

Let’s watch as our changes to a file move from our editor to the staging area and into long-term storage. First, we’ll add another line to the file:
OUTPUT
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
But the Mummy will appreciate the lack of humidityOUTPUT
diff --git a/mars.txt b/mars.txt
index 315bf3a..b36abfd 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1,2 +1,3 @@
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
+But the Mummy will appreciate the lack of humiditySo far, so good: we’ve added one line to the end of the file (shown
with a + in the first column). Now let’s put that change in
the staging area and see what git diff reports:
There is no output: as far as Git can tell, there’s no difference between what it’s been asked to save permanently and what’s currently in the directory. However, if we do this:
OUTPUT
diff --git a/mars.txt b/mars.txt
index 315bf3a..b36abfd 100644
--- a/mars.txt
+++ b/mars.txt
@@ -1,2 +1,3 @@
Cold and dry, but everything is my favorite color
The two moons may be a problem for Wolfman
+But the Mummy will appreciate the lack of humidityit shows us the difference between the last committed change and what’s in the staging area. Let’s save our changes:
OUTPUT
[main 005937f] Discuss concerns about Mars' climate for Mummy
1 file changed, 1 insertion(+)check our status:
OUTPUT
On branch main
nothing to commit, working tree cleanand look at the history of what we’ve done so far:
OUTPUT
commit 005937fbe2a98fb83f0ade869025dc2636b4dad5 (HEAD -> main)
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 10:14:07 2013 -0400
Discuss concerns about Mars' climate for Mummy
commit 34961b159c27df3b475cfe4415d94a6d1fcd064d
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 10:07:21 2013 -0400
Add concerns about effects of Mars' moons on Wolfman
commit f22b25e3233b4645dabd0d81e651fe074bd8e73b
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 09:51:46 2013 -0400
Start notes on Mars as a baseSometimes, e.g. in the case of the text documents a line-wise diff is
too coarse. That is where the --color-words option of
git diff comes in very useful as it highlights the changed
words using colors.
When the output of git log is too long to fit in your
screen, git uses a program to split it into pages of the
size of your screen. When this “pager” is called, you will notice that
the last line in your screen is a :, instead of your usual
prompt.
- To get out of the pager, press Q.
- To move to the next page, press Spacebar.
- To search for
some_wordin all pages, press / and typesome_word. Navigate through matches pressing N.
To avoid having git log cover your entire terminal
screen, you can limit the number of commits that Git lists by using
-N, where N is the number of commits that you
want to view. For example, if you only want information from the last
commit you can use:
OUTPUT
commit 005937fbe2a98fb83f0ade869025dc2636b4dad5 (HEAD -> main)
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 10:14:07 2013 -0400
Discuss concerns about Mars' climate for MummyYou can also reduce the quantity of information using the
--oneline option:
OUTPUT
005937f (HEAD -> main) Discuss concerns about Mars' climate for Mummy
34961b1 Add concerns about effects of Mars' moons on Wolfman
f22b25e Start notes on Mars as a baseYou can also combine the --oneline option with others.
One useful combination adds --graph to display the commit
history as a text-based graph and to indicate which commits are
associated with the current HEAD, the current branch
main, or other
Git references:
OUTPUT
* 005937f (HEAD -> main) Discuss concerns about Mars' climate for Mummy
* 34961b1 Add concerns about effects of Mars' moons on Wolfman
* f22b25e Start notes on Mars as a baseDirectories
Two important facts you should know about directories in Git.
- Git does not track directories on their own, only files within them. Try it for yourself:
Note, our newly created empty directory spaceships does
not appear in the list of untracked files even if we explicitly add it
(via git add) to our repository. This is the
reason why you will sometimes see .gitkeep files in
otherwise empty directories. Unlike .gitignore, these files
are not special and their sole purpose is to populate a directory so
that Git adds it to the repository. In fact, you can name such files
anything you like.
- If you create a directory in your Git repository and populate it with files, you can add all files in the directory at once by:
Try it for yourself:
BASH
$ touch spaceships/apollo-11 spaceships/sputnik-1
$ git status
$ git add spaceships
$ git statusBefore moving on, we will commit these changes.
To recap, when we want to add changes to our repository, we first
need to add the changed files to the staging area (git add)
and then commit the staged changes to the repository
(git commit):

Committing Changes to Git
Which command(s) below would save the changes of
myfile.txt to my local Git repository?
- Would only create a commit if files have already been staged.
- Would try to create a new repository.
- Is correct: first add the file to the staging area, then commit.
- Would try to commit a file “my recent changes” with the message myfile.txt.
Committing Multiple Files
The staging area can hold changes from any number of files that you want to commit as a single snapshot.
- Add some text to
mars.txtnoting your decision to consider Venus as a base - Create a new file
venus.txtwith your initial thoughts about Venus as a base for you and your friends - Add changes from both files to the staging area, and commit those changes.
The output below from cat mars.txt reflects only content
added during this exercise. Your output may vary.
First we make our changes to the mars.txt and
venus.txt files:
OUTPUT
Maybe I should start with a base on Venus.OUTPUT
Venus is a nice planet and I definitely should consider it as a base.Now you can add both files to the staging area. We can do that in one line:
Or with multiple commands:
Now the files are ready to commit. You can check that using
git status. If you are ready to commit use:
OUTPUT
[main cc127c2]
Write plans to start a base on Venus
2 files changed, 2 insertions(+)
create mode 100644 venus.txtThis is an optional aside if it comes up or if there is enough time to address it.
Briefly mention the concept of ignoring files with a .gitignore file and direct learners to additional resources.
Along the lines of “What if we have files that we do not want Git to
track for us, like backup files created by our editor or intermediate
files created during data analysis? Putting these files under version
control would be a waste of disk space. What’s worse, having them all
listed could distract us from changes that actually matter, so we can
tell Git to ignore them. We can do this by creating a file in the root
directory of our project called .gitignore. As a bonus,
using .gitignore helps us avoid accidentally adding files
to the repository that we don’t want to track.”
-
git statusshows the status of a repository. - Files can be stored in a project’s working directory (which users see), the staging area (where the next commit is being built up) and the local repository (where commits are permanently recorded).
-
git addputs files in the staging area. -
git commitsaves the staged content as a new commit in the local repository. -
git logshows the commit history &git diffthe difference between 2 commits. - Write a commit message that accurately describes your changes.
Content from Remotes in GitHub
Last updated on 2025-05-22 | Edit this page
Estimated time: 45 minutes
Overview
Questions
- How do I share my changes with others on the web?
Objectives
- Explain what remote repositories are and why they are useful.
- Push to or pull from a remote repository.
There are no slides associated with this episode. Take a dedicated moment right before this episode to check succesful completion of particpants’ SSH setup and help out people who did not succeed yet. You will need 15-30 minutes for this, so prepare an optional exercise for people that are correctly setup.
Version control really comes into its own when we begin to collaborate with other people. We already have most of the machinery we need to do this; the only thing missing is to copy changes from one repository to another.
Systems like Git allow us to move work between any two repositories. In practice, though, it’s easiest to use one copy as a central hub, and to keep it on the web rather than on someone’s laptop. Most programmers use hosting services like GitHub, Bitbucket or GitLab to hold those main copies.
Let’s start by sharing the changes we’ve made to our current project with the world. To this end we are going to create a remote repository that will be linked to our local repository.
1. Create a remote repository
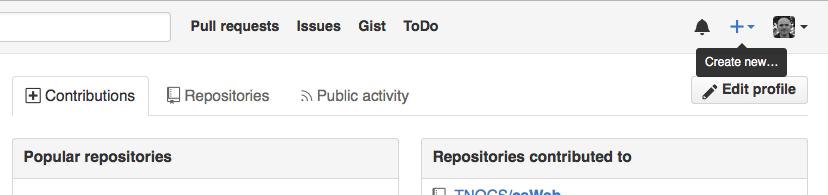
Log in to GitHub, then click on the
icon in the top right corner to create a new repository called
planets:
Name your repository “planets” and then click “Create Repository”.
Note: Since this repository will be connected to a local repository, it needs to be empty. Leave “Initialize this repository with a README” unchecked, and keep “None” as options for both “Add .gitignore” and “Add a license.” See the “GitHub License and README files” exercise below for a full explanation of why the repository needs to be empty.
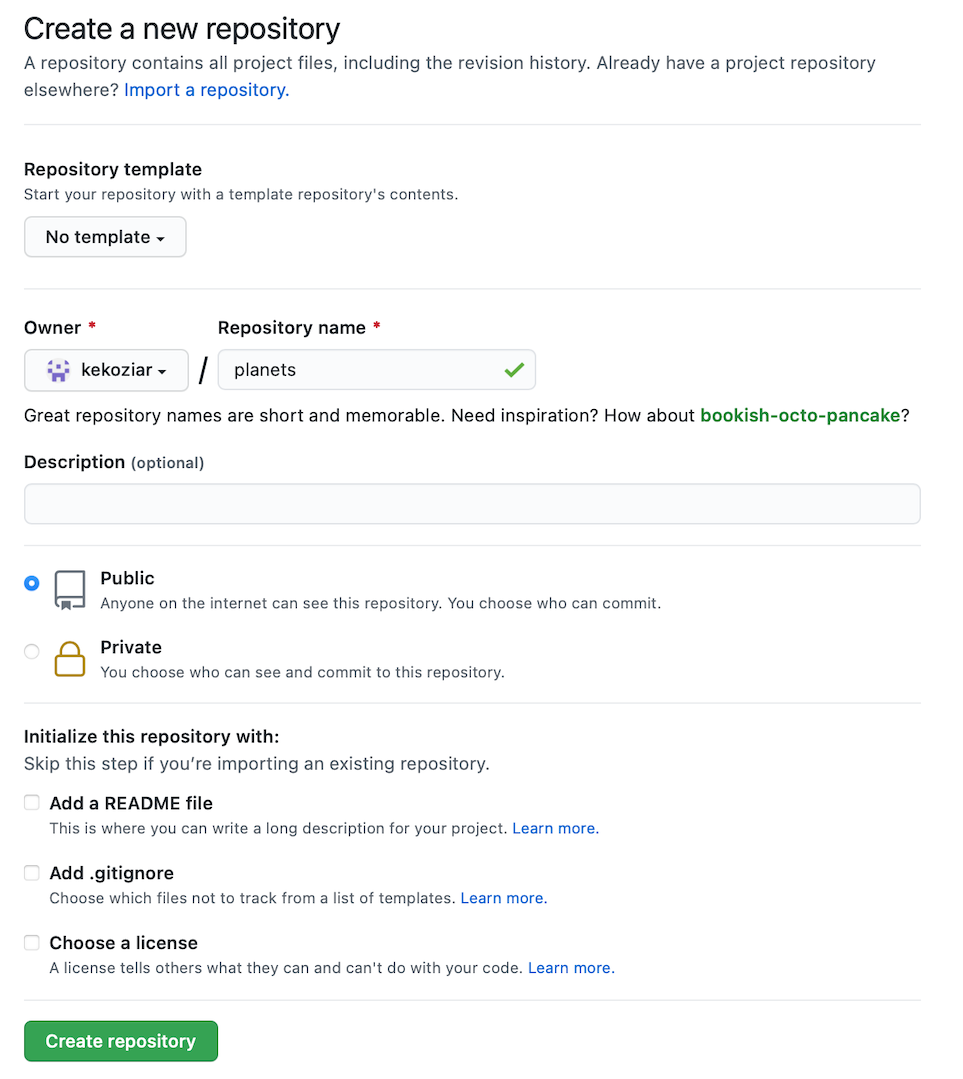
As soon as the repository is created, GitHub displays a page with a URL and some information on how to configure your local repository:
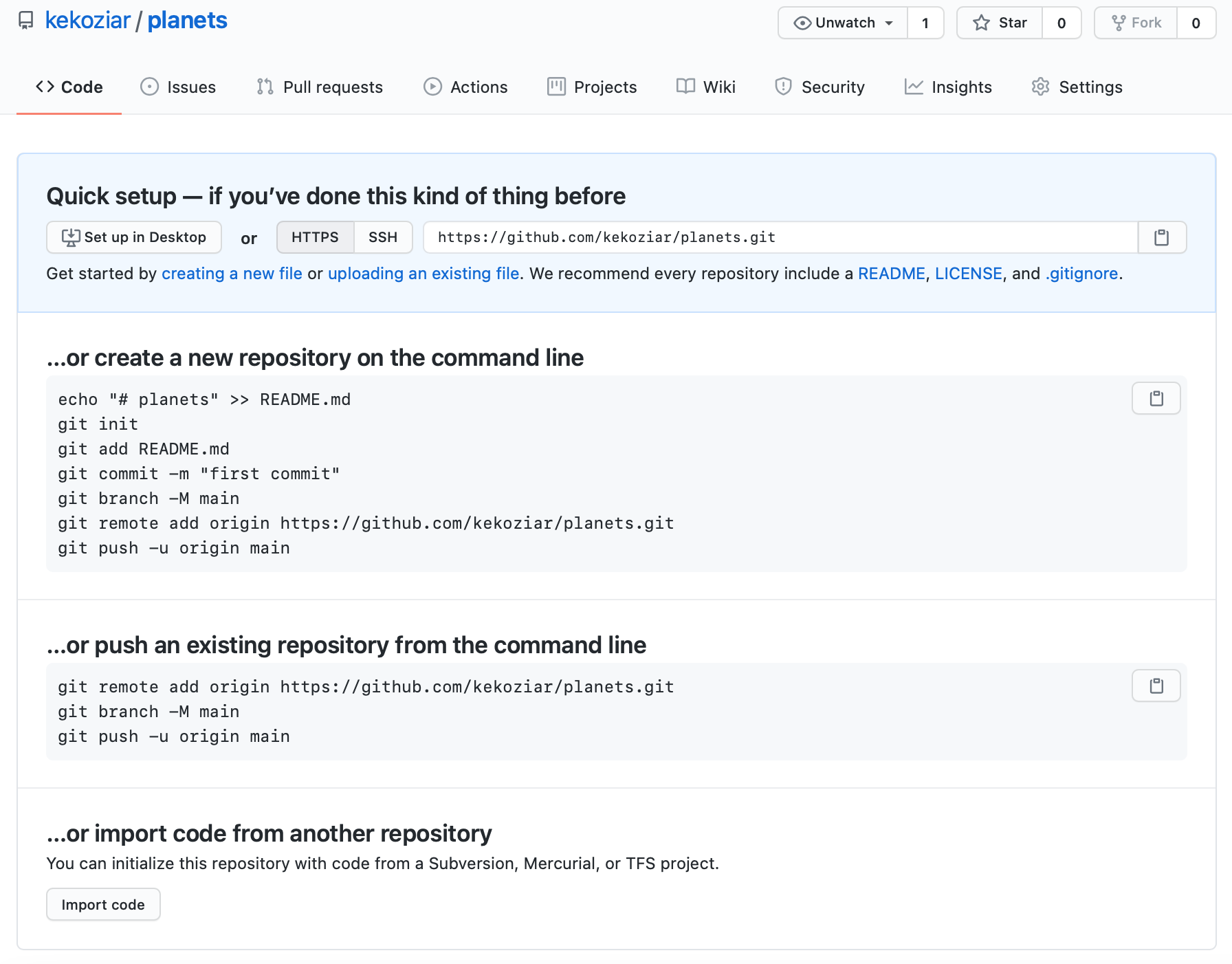
This effectively does the following on GitHub’s servers:
If you remember back to the earlier episode where we added and committed our
earlier work on mars.txt, we had a diagram of the local
repository which looked like this:
Now that we have two repositories, we need a diagram like this:

Note that our local repository still contains our earlier work on
mars.txt, but the remote repository on GitHub appears empty
as it doesn’t contain any files yet.
2. Connect local to remote repository
Now we connect the two repositories. We do this by making the GitHub repository a remote for the local repository. The home page of the repository on GitHub includes the URL string we need to identify it:

Click on the ‘SSH’ link to change the protocol from HTTPS to SSH.
HTTPS vs. SSH
We use SSH here because, while it requires some additional configuration, it is a security protocol widely used by many applications. The steps below describe SSH at a minimum level for GitHub.

Copy that URL from the browser, go into the local
planets repository, and run this command:
Make sure to use the URL for your repository rather than Vlad’s: the
only difference should be your username instead of
vlad.
origin is a local name used to refer to the remote
repository. It could be called anything, but origin is a
convention that is often used by default in git and GitHub, so it’s
helpful to stick with this unless there’s a reason not to.
We can check that the command has worked by running
git remote -v:
OUTPUT
origin git@github.com:vlad/planets.git (fetch)
origin git@github.com:vlad/planets.git (push)We’ll discuss remotes in more detail in the next episode, while talking about how they might be used for collaboration.
3. Push local changes to a remote
Now that authentication is setup, we can return to the remote. This command will push the changes from our local repository to the repository on GitHub:
Since Dracula set up a passphrase, it will prompt him for it. If you completed advanced settings for your authentication, it will not prompt for a passphrase.
OUTPUT
Enumerating objects: 16, done.
Counting objects: 100% (16/16), done.
Delta compression using up to 8 threads.
Compressing objects: 100% (11/11), done.
Writing objects: 100% (16/16), 1.45 KiB | 372.00 KiB/s, done.
Total 16 (delta 2), reused 0 (delta 0)
remote: Resolving deltas: 100% (2/2), done.
To https://github.com/vlad/planets.git
* [new branch] main -> mainIf the network you are connected to uses a proxy, there is a chance that your last command failed with “Could not resolve hostname” as the error message. To solve this issue, you need to tell Git about the proxy:
BASH
$ git config --global http.proxy http://user:password@proxy.url
$ git config --global https.proxy https://user:password@proxy.urlWhen you connect to another network that doesn’t use a proxy, you will need to tell Git to disable the proxy using:
If your operating system has a password manager configured,
git push will try to use it when it needs your username and
password. For example, this is the default behavior for Git Bash on
Windows. If you want to type your username and password at the terminal
instead of using a password manager, type:
in the terminal, before you run git push. Despite the
name, Git
uses SSH_ASKPASS for all credential entry, so you may
want to unset SSH_ASKPASS whether you are using Git via SSH
or https.
You may also want to add unset SSH_ASKPASS at the end of
your ~/.bashrc to make Git default to using the terminal
for usernames and passwords.
Our local and remote repositories are now in this state:

The ‘-u’ Flag
You may see a -u option used with git push
in some documentation. This option is synonymous with the
--set-upstream-to option for the git branch
command, and is used to associate the current branch with a remote
branch so that the git pull command can be used without any
arguments. To do this, simply use git push -u origin main
once the remote has been set up.
We can pull changes from the remote repository to the local one as well:
OUTPUT
From https://github.com/vlad/planets
* branch main -> FETCH_HEAD
Already up-to-date.Pulling has no effect in this case because the two repositories are already synchronized. If someone else had pushed some changes to the repository on GitHub, though, this command would download them to our local repository.
Spend some time showing student around the repository and where to find history on commits etc.
Github also allows you to skip the command line and upload files directly to your repository without having to leave the browser. There are two options. First you can click the “Upload files” button in the toolbar at the top of the file tree. Or, you can drag and drop files from your desktop onto the file tree. You can read more about this on this GitHub page.
Push vs. Commit
In this episode, we introduced the “git push” command. How is “git push” different from “git commit”?
When we push changes, we’re interacting with a remote repository to update it with the changes we’ve made locally (often this corresponds to sharing the changes we’ve made with others). Commit only updates your local repository.
In this episode we learned about creating a remote repository on GitHub, but when you initialized your GitHub repo, you didn’t add a README.md or a license file. If we had, we’d see a merge conflict due to unrelated histories. When GitHub creates a README.md file, it performs a commit in the remote repository. When you try to pull the remote repository to your local repository, Git detects that they have histories that do not share a common origin and refuses to merge.
You can force git to merge the two repositories with the option
--allow-unrelated-histories. Be careful when you use this
option and carefully examine the contents of local and remote
repositories before merging.
Another option would be to first create the repository on GitHub before writing any code and pull the repository locally with:
Take students through the workflow of creating and cloning a repo from GitHub or cloning an existing repository that you want to work with.
- A local Git repository can be connected to one or more remote repositories.
- Use the SSH protocol to connect to remote repositories.
-
git pushcopies changes from a local repository to a remote repository. -
git pullcopies changes from a remote repository to a local repository.
Content from Branches
Last updated on 2025-04-28 | Edit this page
Estimated time: 5 minutes
Overview
Questions
- Understand what branches are and when to use them
Objectives
- What are branches?
Using the slides, explain what branches are and when to use them. You can choose to introduce the commands here, but we will practice with the git commands in the next episode as well.
What are branches and when to use them?
Have a look at these slides introducing branches.
Commands related to branches
Here are some commands related to branches that you often use in practice.
Create a new branch and switch onto it:
git switch -c new-branch-nameOUTPUT
Switched to a new branch 'new-branch-name'Switch to an existing branch, for example back to
main:
git switch mainOUTPUT
Switched to branch 'main'Often while working on a branch, the main branch has changes that you want to apply to the branch you are working on. You can do this by pulling changes from the main branch into the branch that you are working on:
git switch branch-name # Make sure you are on the branch into which you want to pull changes from main
git pull origin main- A branch represents an independent line of development.
- Subsequent changes are considered to belong to that branch.
Content from Collaborative Version Control - Centralized
Last updated on 2025-05-22 | Edit this page
Estimated time: 120 minutes
Overview
Questions
- How can I use version control to collaborate with internal collaborators?
Objectives
- Understand the basics of collaborative version control with git and Github
- Understand the centralized workflow
Teaching is done as a pair of instructors. Instructor A acts as the owner of the repository, instructor B as a collaborator (internal or external).
First we show the centralized workflow all in the browser using Github:
- instructor A creates an issue (for example create ‘sum’ function)
- instructor B picks up the issue
- Instructor B clones the repository
- Instructor B creates a new branch, using
git switch -c new_feature - Instructor B does some reviewable changes (a simple ‘sum’ function)
- Instructor B pushes the changes to the remote repository on GitHub
using
git push origin new_feature - Instructor B opens a new pull request.
- Instructor A reviews and approves the PR.
- Instructor B merges the pull request.
- Use Github repo’s insights -> network to visualize what just happened
Exercise: Working as a project collaborator (in pairs):
- PERSON A: Create an issue in the repository
- PERSON B: Clone this repository to your system
- PERSON B: Create a new branch, using
git switch -c new_feature - PERSON B: Make the changes requested in the issue
- PERSON B: Push the changes to the remote repository on GitHub using
git push origin new_feature - PERSON B: Submit a Pull Request, refer to the issue (e.g. “Closes #1”)
- PERSON A: Review the Pull Request
- PERSON B: Address the comments
- PERSON A: Approve the Pull Request
- PERSON B: Merge the Pull Request
- Git and Github are superpowerful, not just for version control, but as tools for collaborative development
- Do code reviews and be constructive in them!
- Use centralized flow for internal collaborations